Creo l'ambiente di test contenente la tabella partizionata MYPARTITIONTABLE e la tabella NON partizionata NORMALTABLE. Entrambe hanno gli stessi campi e avranno gli stessi indici.
USE MASTER
Go
CREATE DATABASE DB_Test_Partition
Go
ALTER DATABASE [DB_TEST_PARTITION] ADD FILEGROUP [PartizioneUno]
GO
ALTER DATABASE [DB_TEST_PARTITION] ADD FILEGROUP [PartizioneDue]
GO
ALTER DATABASE [DB_TEST_PARTITION] ADD FILEGROUP [PartizioneTre]
GO
ALTER DATABASE [DB_TEST_PARTITION] ADD FILEGROUP [PartizioneQuattro]
GO
ALTER DATABASE [DB_TEST_PARTITION] ADD FILE ( NAME = N'p1', FILENAME = N'C:\Sql Server 2012\UserDataBase\p1.ndf') TO FILEGROUP [PartizioneUno]
GO
ALTER DATABASE [DB_TEST_PARTITION] ADD FILE ( NAME = N'p2', FILENAME = N'C:\Sql Server 2012\UserDataBase\p2.ndf') TO FILEGROUP [PartizioneDue]
GO
ALTER DATABASE [DB_TEST_PARTITION] ADD FILE ( NAME = N'p3', FILENAME = N'C:\Sql Server 2012\UserDataBase\p3.ndf') TO FILEGROUP [PartizioneTre]
GO
ALTER DATABASE [DB_TEST_PARTITION] ADD FILE ( NAME = N'p4', FILENAME = N'C:\Sql Server 2012\UserDataBase\p4.ndf') TO FILEGROUP [PartizioneQuattro]
GO
USE DB_TEST_PARTITION
Go
CREATE PARTITION FUNCTION MYPARTITIONFUNCTION (int)
AS RANGE LEFT FOR VALUES (500, 1000, 1500) ;
GO
CREATE PARTITION SCHEME MYPARTITIONSCHEME
AS PARTITION MYPARTITIONFUNCTION
TO (PartizioneUno, PartizioneDue, PartizioneTre, PartizioneQuattro) ;
GO
--Creo la tabella in modo che ogni record allochi una datapages
--e la partiziono con il partitioning schema appena creato
CREATE TABLE MYPARTITIONTABLE
(
col1 int not null,
col2 char(400) not null,
col3 char(400) not null,
col4 char(400) not null,
col5 char(4000)
)ON MYPARTITIONSCHEME (col1) ;
GO
CREATE TABLE NORMALTABLE
(
col1 int not null,
col2 char(400) not null,
col3 char(400) not null,
col4 char(400) not null,
col5 char(4000)
);
GO
--La popolo con 2000 record, 500 per ogni partizione
;with CtePopolaTab
as
(Select 1 Riga union All Select 1 Riga),
Cte4 as (Select A.* from CtePopolaTab A,CtePopolaTab B),
Cte16 as (Select A.* from Cte4 A,Cte4 B),
Cte256 as (Select A.* from Cte16 A,Cte16 B),
Cte65536 as (Select A.* from Cte256 A,Cte256 B),
Ctex as (Select A.* from Cte65536 A,Cte65536 B),
Risultato as (Select ROW_NUMBER() over(Order by riga) Riga from Ctex )
Insert Into MYPARTITIONTABLE
Select Riga
,Riga
,Riga
,Riga
,Riga
from Risultato
Where Riga <= 2000
--La popolo con 2000 record
;with CtePopolaTab
as
(Select 1 Riga union All Select 1 Riga),
Cte4 as (Select A.* from CtePopolaTab A,CtePopolaTab B),
Cte16 as (Select A.* from Cte4 A,Cte4 B),
Cte256 as (Select A.* from Cte16 A,Cte16 B),
Cte65536 as (Select A.* from Cte256 A,Cte256 B),
Ctex as (Select A.* from Cte65536 A,Cte65536 B),
Risultato as (Select ROW_NUMBER() over(Order by riga) Riga from Ctex )
Insert Into NORMALTABLE
Select Riga
,Riga
,Riga
,Riga
,Riga
from Risultato
Where Riga <= 2000
Select
Proviamo subito ad implementare una lettura dei dati di entrambe le tabelle. Abilitiamo l'opzione "Include Actual Execution Plan" da SSMS.
Checkpoint; Dbcc dropcleanbuffers Go --Abilito la visualizzazione delle statistiche di I/O Set statistics IO on Go Select col2 from MYPARTITIONTABLE Where Col2 = '500' Go Select col2 from NORMALTABLE Where Col2 = '500' Go

Ovviamente, non essendoci alcun index il piano d'esecuzione implementa una tablescan, in pratica legge tutte le righe contenute nella tabella dalla prima riga della prima data page all'ultima riga dell'ultima data page in entrambe le tabelle.
Quante letture sono implementate ?
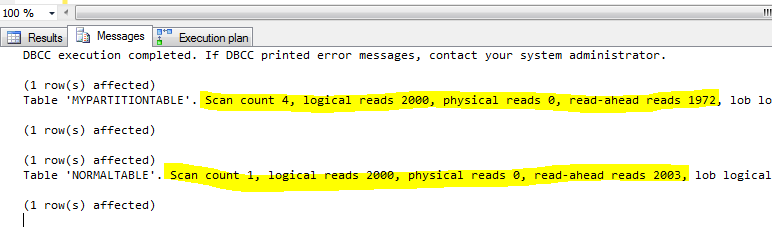
Proviamo a creare un indice noncluster allineato sulla colonna col2 di entrambe le tabelle e ad implementare una ricerca. Col2 non è la colonna di partizionamento per MYPARTITIONTABLE.
create nonclustered Index idxPartitioned on MYPARTITIONTABLE(col2) e rieseguiamo le select precedenti. Go create nonclustered Index idxNormal on NORMALTABLE(col2) Go Checkpoint; Dbcc dropcleanbuffers Go --Abilito la visualizzazione delle statistiche di I/O Set statistics IO on Go Select col2 from MYPARTITIONTABLE where col2 = '500' Go Select col2 from NORMALTABLE where col2 = '500' Go
Questi i piani d'esecuzione.

La select implementata sulla tabella partizionata ha un costo dell'80% nel batch. Non fermiamoci all'apparenza però !
Guardiamo le statistiche di IO


Actual Partition Count indica quante partizioni sono accedute per risolvere la query, nel nostro caso 4. Ma perchè ? Perchè non abbiamo specificato un filtro su col1, colonna di partizionamento, quindi deve cercare in tutte le partizioni col2 = '500'. Questo è confermato dal doppio Seek visualizzato nel Seek Predicate dell'operatore. Il primo seek tenta di identificare quale partizione contiene il subset di dati che ci interessa, il secondo seek ricerca il valore '500' in col2.
Vediamo come cambia il piano d'esecuzione aggiungendo un filtro anche su col1.
Checkpoint; Dbcc dropcleanbuffers Go --Abilito la visualizzazione delle statistiche di I/O Set statistics IO on Go Select col2 from MYPARTITIONTABLE where col2 = '500' and col1=500 Go

viene ovviamente implementato un index seek come nel caso precedente ma questa volta Actual Partition Count è 1 e Seek Predicate ha un solo Seek.
E l'IO ?

E' diminuito, è praticamente identico a quello della tabella non partizionata.
Quando implementiamo ricerche di record specifici su tabelle partizionate è buona norma implementare un filtro anche sulla colonna di partizionamento altrimenti rischieremmo di ottenere performance scadenti dovute all'accesso di tutte le partizioni della tabella con un elevato numero di letture.
Se implementiamo il partizionamento di una tabella preesistente è bene controllare sp, view, fn e query per essere certi che implementino query adeguate, cioè con il filtro anche sulla colonna di partitioning.
Manutenzione
Un grosso vantaggio delle tabelle partizionate è che è possibile implementare la REBUILD o REORGANIZE di ogni singola partizione separatamente.
Prendiamo la nostra tabella MYPARTITIONTABLE ed immaginiamo che venga utilizzata in scrittura la sola partizione 4, mentre le altre contengono esclusivamente dati storici e sono quindi accedute in sola lettura.
Controlliamo lo stato attuale di frammentazione di entrambe le tabelle
Select object_name(pis.object_id) tablename
,ISNULL(i.name,'HEAP') indexname
,pis.partition_number
,pis.index_depth
,pis.avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id('MYPARTITIONTABLE'),Null,null,'LIMITED') pis
Inner join sys.indexes i on pis.object_id = i.object_id and pis.index_id = i.index_id
Select object_name(pis.object_id) tablename
,ISNULL(i.name,'HEAP') indexname
,pis.partition_number
,pis.index_depth
,pis.avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id('NORMALTABLE'),Null,null,'LIMITED')pis
Inner join sys.indexes i on pis.object_id = i.object_id and pis.index_id = i.index_id

Come vedete il valore della colonna avg_fragmentation_in_percent per gli indici in entrambi i casi è 0.
Causiamo un po di frammentazione.
Inserisco 2000 righe con valore di col1 maggiore di 2000, quindi verranno inserite nella partizione 4 in MYPARTITIONTABLE.
;with CtePopolaTab as (Select 1 Riga union All Select 1 Riga), Cte4 as (Select A.* from CtePopolaTab A,CtePopolaTab B), Cte16 as (Select A.* from Cte4 A,Cte4 B), Cte256 as (Select A.* from Cte16 A,Cte16 B), Cte65536 as (Select A.* from Cte256 A,Cte256 B), Ctex as (Select A.* from Cte65536 A,Cte65536 B), Risultato as (Select ROW_NUMBER() over(Order by riga) Riga from Ctex ) Insert Into MYPARTITIONTABLE Select Riga ,Riga ,Riga ,Riga ,Riga from Risultato Where Riga >= 2000 and riga <=4000 ;with CtePopolaTab as (Select 1 Riga union All Select 1 Riga), Cte4 as (Select A.* from CtePopolaTab A,CtePopolaTab B), Cte16 as (Select A.* from Cte4 A,Cte4 B), Cte256 as (Select A.* from Cte16 A,Cte16 B), Cte65536 as (Select A.* from Cte256 A,Cte256 B), Ctex as (Select A.* from Cte65536 A,Cte65536 B), Risultato as (Select ROW_NUMBER() over(Order by riga) Riga from Ctex ) Insert Into NORMALTABLE Select Riga ,Riga ,Riga ,Riga ,Riga from Risultato Where Riga >= 2000 and riga <=4000
Rieseguiamo la query di test del livello di frammentazione.
L'indice MYPARTITIONTABLE.idxPartitioned è frammentato solo per quanto riguarda la partizione 4, mentre NORMALTABLE.idxNormal è totalmente frammentato.

Per l'indice MYPARTITIONTABLE.idxPartitioned possiamo ricostruire solo partizione 4, mentre per NORMALTABLE.idxNormal dobbiamo procedere alla ricostruzione totale dell'indice.
Set statistics Io on Go alter Index idxPartitioned on MYPARTITIONTABLE REBUILD PARTITION = 4 Go alter Index idxNormal on NORMALTABLE REBUILD Go

In questo caso il vantaggio è evidente....
Non solo, possiamo decidere di comprimere i dati delle partizioni in sola lettura risparmiando così spazio su disco e soprattutto IO in fase di lettura.
--Scopro quanto spazio occupa la tabella MYPARTITIONTABLE exec sp_spaceused 'MYPARTITIONTABLE'Procedo alla compressione delle partizioni

alter table MYPARTITIONTABLE REBUILD PARTITION=ALL WITH ( DATA_COMPRESSION = PAGE ON PARTITIONS (1,2,3), DATA_COMPRESSION = NONE ON PARTITIONS(4) ) alter Index idxPartitioned on MYPARTITIONTABLE REBUILD PARTITION=ALL WITH ( DATA_COMPRESSION = PAGE ON PARTITIONS (1,2,3), DATA_COMPRESSION = NONE ON PARTITIONS(4) )
Rieseguiamo la verifica dello spazio allocato

che ovviamente è diminuito.
Ciao
Luca
Nessun commento:
Posta un commento