Ricostruire gli indici è un'operazione che andrebbe effettuata in modo frequente soprattutto nei database OLTP che subiscono moltissime scritture ed allo stesso tempo moltissime letture al fine di mantenere elevato il grado delle performance nelle fasi di ricerca.
Grazie all'opzione ONLINE = ON possiamo ricostruire gli indici e anche durante questa fase assicurare alle altre connessioni una normale operatività.
Se però una transazione dovesse rimanere in esecuzione per lungo tempo la rebuild non proseguirebbe la sua attività fino a che le risorse in uso dalla transazione non torneranno disponibili.
Fino alla versione 2012 era possibile eseguire il rebuild online di una tabella senza specificare per quanto tempo l'operazione avesse dovuto attendere per accedere ad una risorsa in uso da un'altra connessione. In pratica non era possibile decidere se dare "precedenza" all'operazione di rebuild o alla query.
Inoltre la rebuild di una singola partizione di una tabella non era supportata.
Con l'attuale versione durante un'operazione di rebuild on line, qualora una transazione blocchi delle risorse nella tabella, la rebuild stessa viene sospesa in attesa che la transazione bloccante rilasci le risorse. Se la transazione, per un qualche errore dovesse rimanere appesa per un lungo periodo, la rebuild non si potrebbe completare in tempo utile.
Vediamo cosa accade
Su un'istanza SQL Server 2012 Sp1 Enterprise creo un database contenente una tabella partizionata [TestTable] e la popolo con 4 milioni di righe.
USE MASTER GO CREATE DATABASE TestRebuild2012 Go ALTER DATABASE TestRebuild2012 ADD FILEGROUP [PartizioneUno] GO ALTER DATABASE TestRebuild2012 ADD FILEGROUP [PartizioneDue] GO ALTER DATABASE TestRebuild2012 ADD FILEGROUP [PartizioneTre] GO ALTER DATABASE TestRebuild2012 ADD FILEGROUP [PartizioneQuattro] GO ALTER DATABASE TestRebuild2012 ADD FILE ( NAME = N'p1', FILENAME = N'E:\SQL2012_MSSQLSERVER\User Database\p1.ndf') TO FILEGROUP [PartizioneUno] GO ALTER DATABASE TestRebuild2012 ADD FILE ( NAME = N'p2', FILENAME = N'E:\SQL2012_MSSQLSERVER\User Database\p2.ndf') TO FILEGROUP [PartizioneDue] GO ALTER DATABASE TestRebuild2012 ADD FILE ( NAME = N'p3', FILENAME = N'E:\SQL2012_MSSQLSERVER\User Database\p3.ndf') TO FILEGROUP [PartizioneTre] GO ALTER DATABASE TestRebuild2012 ADD FILE ( NAME = N'p4', FILENAME = N'E:\SQL2012_MSSQLSERVER\User Database\p4.ndf') TO FILEGROUP [PartizioneQuattro] GO USE TestRebuild2012 Go CREATE PARTITION FUNCTION testPF (int) AS RANGE LEFT FOR VALUES (1000000, 2000000, 3000000); Go CREATE PARTITION SCHEME testScheme AS PARTITION testPF TO ( [PartizioneUno],[PartizioneDue],[PartizioneTre],[PartizioneQuattro] ); Go CREATE TABLE TestTable ( id INT ,campo VARCHAR(25) ,valore VARCHAR(25) ) ON testScheme(id) CREATE CLUSTERED INDEX idxClustered on TestTable(id) ;WITH Cte as (SELECT 1 Riga UNION ALL SELECT 1) ,Cte4 as (SELECT A.Riga FROM Cte A, Cte B) ,Cte16 as (SELECT A.Riga FROM Cte4 A, Cte4 B) ,Cte256 as (SELECT A.Riga FROM Cte16 A, Cte16 B) ,Cte65536 as (SELECT A.Riga FROM Cte256 A, Cte256 B) ,CteBig as (SELECT A.Riga FROM Cte65536 A, Cte65536 B) ,Results as (SELECT ROW_NUMBER()OVER(ORDER BY Riga) Riga FROM CteBig) INSERT INTO TestTable SELECT TOP 4000000 Riga ,'Campo ' + Cast(Riga AS VARCHAR(10)) ,'valore ' + Cast(Riga AS VARCHAR(10)) FROM Results
Apro una connessione ed eseguo la rebuild online dell'indice clustered, cioè della tabella.
ALTER INDEX idxClustered ON TestTable REBUILD WITH (ONLINE = ON)
Da un'altra connessione eseguo la modifica di una sola riga ma non ne faccio il commit (In questo modo mantengo per lungo tempo i Lock sulla risorsa)
BEGIN TRANSACTION UPDATE TestTable SET Valore = 'Mod ' + Valore WHERE id = 1500000
L'activity monitor mostra cosa sta accadendo....
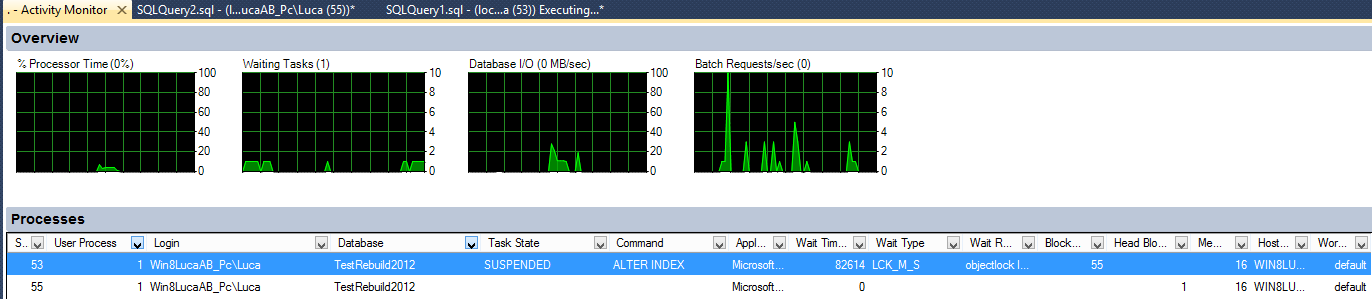
Come potete vedere la rebuild è in stato SUSPENDED, sta attendendo di accedere alla risora in uso dall'update.
Se eseguo il COMMIT o la ROLLBACK dell'operazione di update la rebuild entra in RUNNING e può essere completata.

Con SQL Server 2014 CTP1 è stata introdotta la possibilità di specificare come un'operazione di rebuild online di un indice si deve comportare qualora un'altra transazione stia elaborando una o più righe della tabella stessa.
Su un'istanza SQL Server 2014 CTP1 creo un database contenente una tabella partizionata [TestTable] e la popolo con 4 milioni di righe.
N.B. Il Database ha la stessa identica struttura del suo gemello in versione SQL 2012. Cambia solo il nome ed il path dei file.
CREATE DATABASE TestRebuild2014 Go ALTER DATABASE TestRebuild2014 ADD FILEGROUP [PartizioneUno] GO ALTER DATABASE TestRebuild2014 ADD FILEGROUP [PartizioneDue] GO ALTER DATABASE TestRebuild2014 ADD FILEGROUP [PartizioneTre] GO ALTER DATABASE TestRebuild2014 ADD FILEGROUP [PartizioneQuattro] GO ALTER DATABASE TestRebuild2014 ADD FILE ( NAME = N'p1', FILENAME = N'E:\Data\p1.ndf') TO FILEGROUP [PartizioneUno] GO ALTER DATABASE TestRebuild2014 ADD FILE ( NAME = N'p2', FILENAME = N'E:\Data\p2.ndf') TO FILEGROUP [PartizioneDue] GO ALTER DATABASE TestRebuild2014 ADD FILE ( NAME = N'p3', FILENAME = N'E:\Data\p3.ndf') TO FILEGROUP [PartizioneTre] GO ALTER DATABASE TestRebuild2014 ADD FILE ( NAME = N'p4', FILENAME = N'E:\Data\p4.ndf') TO FILEGROUP [PartizioneQuattro] GO USE TestRebuild2014 Go CREATE PARTITION FUNCTION testPF (int) AS RANGE LEFT FOR VALUES (1000000, 2000000, 3000000); Go CREATE PARTITION SCHEME testScheme AS PARTITION testPF TO ( [PartizioneUno],[PartizioneDue],[PartizioneTre],[PartizioneQuattro] ); Go CREATE TABLE TestTable ( id INT ,campo VARCHAR(25) ,valore VARCHAR(25) ) ON testScheme(id) CREATE CLUSTERED INDEX idxClustered on TestTable(id) ;WITH Cte as (SELECT 1 Riga UNION ALL SELECT 1) ,Cte4 as (SELECT A.Riga FROM Cte A, Cte B) ,Cte16 as (SELECT A.Riga FROM Cte4 A, Cte4 B) ,Cte256 as (SELECT A.Riga FROM Cte16 A, Cte16 B) ,Cte65536 as (SELECT A.Riga FROM Cte256 A, Cte256 B) ,CteBig as (SELECT A.Riga FROM Cte65536 A, Cte65536 B) ,Results as (SELECT ROW_NUMBER()OVER(ORDER BY Riga) Riga FROM CteBig) INSERT INTO TestTable SELECT TOP 4000000 Riga ,'Campo ' + Cast(Riga AS VARCHAR(10)) ,'valore ' + Cast(Riga AS VARCHAR(10)) FROM Results
Provo ad eseguire il rebuild online dell'intera tabella.
ALTER INDEX idxClustered ON TestTable
REBUILD
WITH (
ONLINE = ON
(
WAIT_AT_LOW_PRIORITY
(MAX_DURATION = 1
, ABORT_AFTER_WAIT = BLOCKERS)
)
)
La sintassi prevede delle nuove opzioni :
MAX_DURATION : Tempo massimo (in minuti) d'attesa per accedere alla risorsa.
ABORT_AFTER_WAIT : Al termine del periodo di attesa specificato in MAX_DURATION viene eseguito il Kill dell'operazione bloccante se il parametro è BLOCKERS o della rebuild stessa se il parametro è SELF.
Apro una connessione ed eseguo la modifica di una sola riga ma non ne faccio il commit (In questo modo mantengo per lungo tempo i Lock sulla risorsa)
BEGIN TRANSACTION UPDATE TestTable SET Valore = 'Mod ' + Valore WHERE id = 1500000
Come si comporta quindi l'engine ?
Inizialmente esattamente come se ci trovassimo in SQL Server 2012, la rebuild viene messa in suspend....
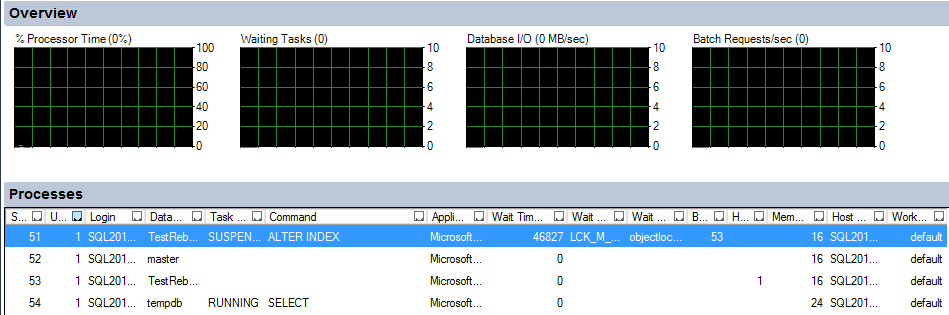
ma dato che abbiamo specificato il parametro MAX_DURATION = 1 la rebuild attende per il tempo max specificato, nel nostro esempio un minuto, scaduto il quale implementa il Kill della/delle transazioni bloccanti. In questo modo la rebuild potrà continuare le sue attività.

Cosa succede alla transazione dell'update se tento di dare il commit ?

Dato che la rebuild ha fatto il Kill della connessione riceve un'errore.
(Automaticamente l'engine ha inoltre implementato la rollback dell'update)
Se avessi specificato il parametro ABORT_AFTER_WAIT = SELF il comportamento sarebbe stato l'opposto, la transazione avrebbe avuto priorità e l'engine avrebbe effettuato la kill della rebuild.
Dato che la tabella è stata creata come partizionata potrei voler effettuare il rebuild online di una sola partizione ma......
L'operazione di rebuild di una sola partizione con Sql Server 2012 non è supportata.

Mentre in Sql Server 2014 CTP1 è possibile fare il rebuild online di una sola partizione
ALTER INDEX idxClustered ON TestTable REBUILD PARTITION = 2 WITH (ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 1, ABORT_AFTER_WAIT = BLOCKERS)))

Se non vengono specificate le opzioni MAX_DURATION e ABORT_AFTER_WAIT il comportamento implementato è quello descritto per SQL Server 2012.
Ciao
Luca
Nessun commento:
Posta un commento