Scopo delle funzioni di ranking è quello di "classificare" ogni riga all'interno di una partizione, di un set di risultati.
Le funzioni di ranking sono 4
1. ROW_NUMBER()
2. RANK()
3. DENSE_RANK()
4. NTILE(n)
Ogni funzione di ranking deve essere seguita dalla clausola OVER() che determina il criterio di partizionamento eventuale e/o il criterio di ordinamento.
Vediamole singolarmente.
Per prima cosa abbiamo bisogno di un ambiente popolato con dati di test, quindi creo un DB che simula, in modo estremamente semplificato, la gestione di clienti, venditori, prodotti e fatture.
N.B: Se eseguite lo script di creazione del DB i risultati numerici potrebbero essere differenti da quelli riportati nel post perchè Data di fatturazione e quantità del prodotto sono generati randomicamente.
Create database RankingTest
Go
Use RankingTest
Go
create table tabVenditori
(
id smallint identity primary key clustered,
Nome varchar(25) Unique not null
)
Go
create table tabClienti
(
id smallint identity primary key clustered,
Nome varchar(25)Unique not null
)
Go
Create table tabProdotti
(
id smallint identity primary key clustered,
CodProd char(5) not null,
Descrizione varchar(50) not null,
Prezzo money not null
)
Go
create table tabIntestazioneVendite
(
id int identity primary key clustered,
idCliente smallint references tabClienti(id) not null,
idVenditore smallint references tabVenditori(id) not null,
data date not null
)
Go
create table tabDettaglioVendite
(
idVendita int references tabIntestazioneVendite(id) not null,
idProdotto smallint references tabProdotti(id) not null,
Qta smallint not null,
constraint PK_Dettaglio primary key clustered (idvendita,idprodotto)
)
Go
--Popolo la tabella tabVenditori
Insert into tabVenditori values('Venditore_A'),('Venditore_B'),('Venditore_C'),('Venditore_D')
Go
--Popolo la tabella tabClienti
Insert into tabClienti values('Cliente_A'),('Cliente_B'),('Cliente_C'),('Cliente_D')
Go
--Popolo la tabella tabProdotti
Insert into tabProdotti values('PRD01','001 Descrizione prodotto 1',12)
,('PRD02','002 Descrizione prodotto 2',41)
,('PRD03','003 Descrizione prodotto 3',12)
,('PRD04','004 Descrizione prodotto 4',87)
,('PRD05','005 Descrizione prodotto 5',2);
Go
/*
Popolo la tabella tabIntestazioneVendite sfruttando le cross join scritte nello standard ansi 89 tra tabVenditori e tabClienti.
Inserisco quindi 16 intestazioni fattura
*/
Insert into tabIntestazioneVendite (idCliente,idVenditore,data)
Select C.id,V.id,(select dateadd(month, -1 * abs(convert(varbinary, newid()) % (90 * 12)), getdate()) as Data) from tabVenditori V,tabClienti C
Go
/*
Popolo la tabella tabDettaglioVendite sfruttando le cross join scritte nello standard ansi 89 tra tabProdotti e tabIntestazioneVendite.
Inserisco quindi 80 righe di dettaglio
*/
Insert into tabDettaglioVendite (idvendita,idProdotto,qta)
Select V.id,P.id,(select convert(smallint, ((DATEPART(month,V.data))*RAND())))+1 from tabProdotti P,tabIntestazioneVendite V
Go
Row_Number()
La funzione Row_Number() consente di numerare arbitrariamente le righe restituite all'interno di una partizione su un determinato criterio di ordinamento.
Tornando al nostro Db ci tornerebbe utile per numerare ed ordinare le fatture dalla più prospicua alla meno prospicua.
Select IV.id ,Sum(DV.qta+P.Prezzo) Importo ,Row_number() over(Order by Sum(DV.qta+P.Prezzo) desc) Classifica from tabIntestazioneVendite IV inner join tabDettaglioVendite DV On DV.idVendita = IV.id inner join tabProdotti P on P.id = DV.idProdotto Group by IV.id Order by Classifica asc
Come potete vedere la clausola over(Order by Sum(DV.qta+P.Prezzo) desc) contiene il criterio di ordinamento basato sulla Sum(DV.qta+P.Prezzo) decrescente. Questo perchè si vuole ottenere che il valore 1 della Row_Number() sia associato alla fattura dall'importo maggiore. La Row_Number() inoltre non lascia buchi nella classificazione delle righe.
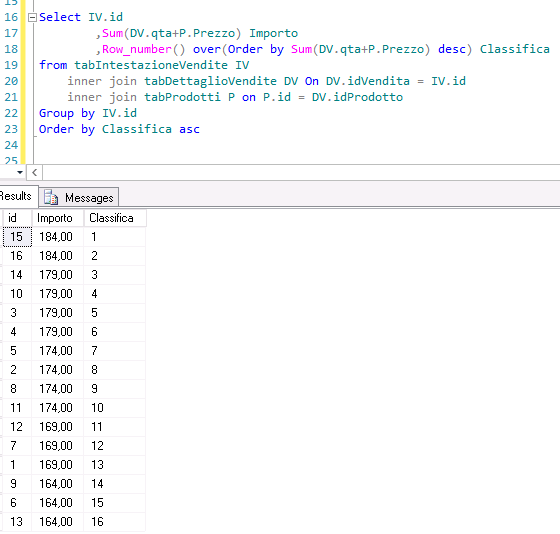
La Row_Number() potrebbe essere utilizzata anche per paginare i dati come potete leggere da qui.
RANK()
La funzione rank() consente di classificare i dati all'interno di un partizionamento e/o ordinamento all'interno di un set di risultati.
Nel nostro caso potremmo utilizzarla per implementare una classificazione dei prodotti di maggior successo del nostro catalogo.
Select P.CodProd [Codice Prodotto] ,sum(DV.Qta*P.Prezzo) ,Rank() Over(Order by sum(DV.Qta*P.Prezzo) desc)Classifica from tabIntestazioneVendite IV inner join tabDettaglioVendite DV On DV.idVendita = IV.id inner join tabProdotti P on P.id = DV.idProdotto Group by P.CodProd Order by Classifica
Fate attenzione ai risultati:

PRD03 e PRD01 hanno fatturato il medesimo importo, la Rank() li classifica nella stessa posizione ma la numerazione riparte da 5. In pratica lascia un buco nella numerazione. Il buco potrebbe essere più o meno ampio, dipende da quanti elementi sono classificati nella stessa posizione.
DENSE_RANK()
La Dense_Rank() funziona quasi esattamente come la Rank() ma non lascia buchi nella numerazione. Vengono quindi coperte tutte le posizioni della classifica.
Select P.CodProd [Codice Prodotto] ,sum(DV.Qta*P.Prezzo) ,Dense_Rank() Over(Order by sum(DV.Qta*P.Prezzo) desc)Classifica from tabIntestazioneVendite IV inner join tabDettaglioVendite DV On DV.idVendita = IV.id inner join tabProdotti P on P.id = DV.idProdotto Group by P.CodProd

NTILE(n)
La Ntile() suddivide le righe di una partizione in un numero specificato (n) di gruppi. Nel nostro caso potremmo utilizzarla per suddividere in 2 gruppi le fatture di ogni venditore
Select IV.id ,IV.idVenditore ,NTile(2) Over(partition by IV.idvenditore order by IV.id)Gruppo from tabIntestazioneVendite IV Order by Gruppo

In quest'ultimo caso abbiamo usato anche la clausola partition, che crea una partizione su idVenditore su cui applicare la funzione Ntile(n) all'interno del set di dati della query.
Ciao
Luca
Nessun commento:
Posta un commento